


A few weeks ago, we wrote a piece published by Techstars about how AI is supercharging developers, rather than simply replacing them. The core premise was simple: you want a human in the loop to anchor the architecture, guide the context, and turn raw AI outputs into shippable products.
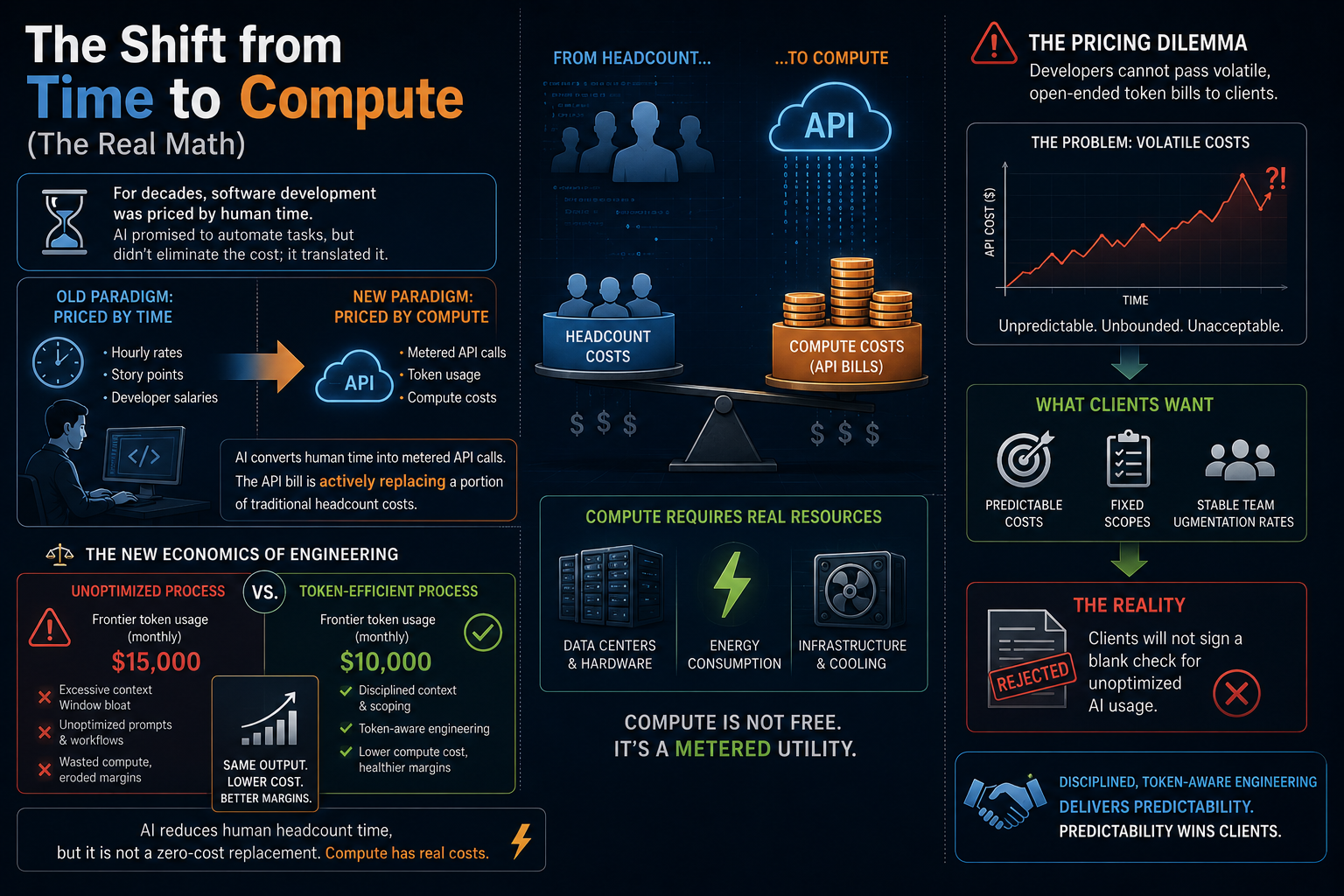
That thesis still holds, but the underlying economics of the industry just changed.
For the past several months, engineers have enjoyed an artificially cheap AI sandbox. The major frontier model providers like OpenAI, Anthropic, and Microsoft, heavily subsidized the true cost of compute to win developer mindshare. Devs got hooked on cheap access, treating frontier models like Claude Opus as if they were standard, flat-rate SaaS applications.`
The honeymoon is over.
As the tech giants behind popular frontier models pivot from market mindshare acquisition to IPO-driven profitability, they are removing the subsidies. An industry-wide shift toward raw, metered, usage-based token pricing is arriving and the illusion of cheap, unlimited AI generation is fast-disappearing. The uncomfortable truth has arrived: AI has transformed software development into a heavily metered utility. Compute is an active infrastructure cost, and if your team isn't managing it with sharp discipline, your engineering overhead is about to explode.
The Cost of "Token Maxing" and Goodhart's Law
When generative AI tools first flooded the engineering ecosystem, the prevailing thought was to burn as many tokens as possible. Industry metrics focused mainly on developer adoption, treating high token consumption as a proxy for hyper-productivity.
Nvidia CEO Jensen Huang famously stated on the All-In Podcast that he would be deeply alarmed if a highly paid software engineer didn't consume at least $250,000 worth of tokens annually. Many organizations took this idea and ran with it, establishing internal leaderboards to track which developers or teams used the most AI prompts, a trend quickly dubbed "Token Maxing."
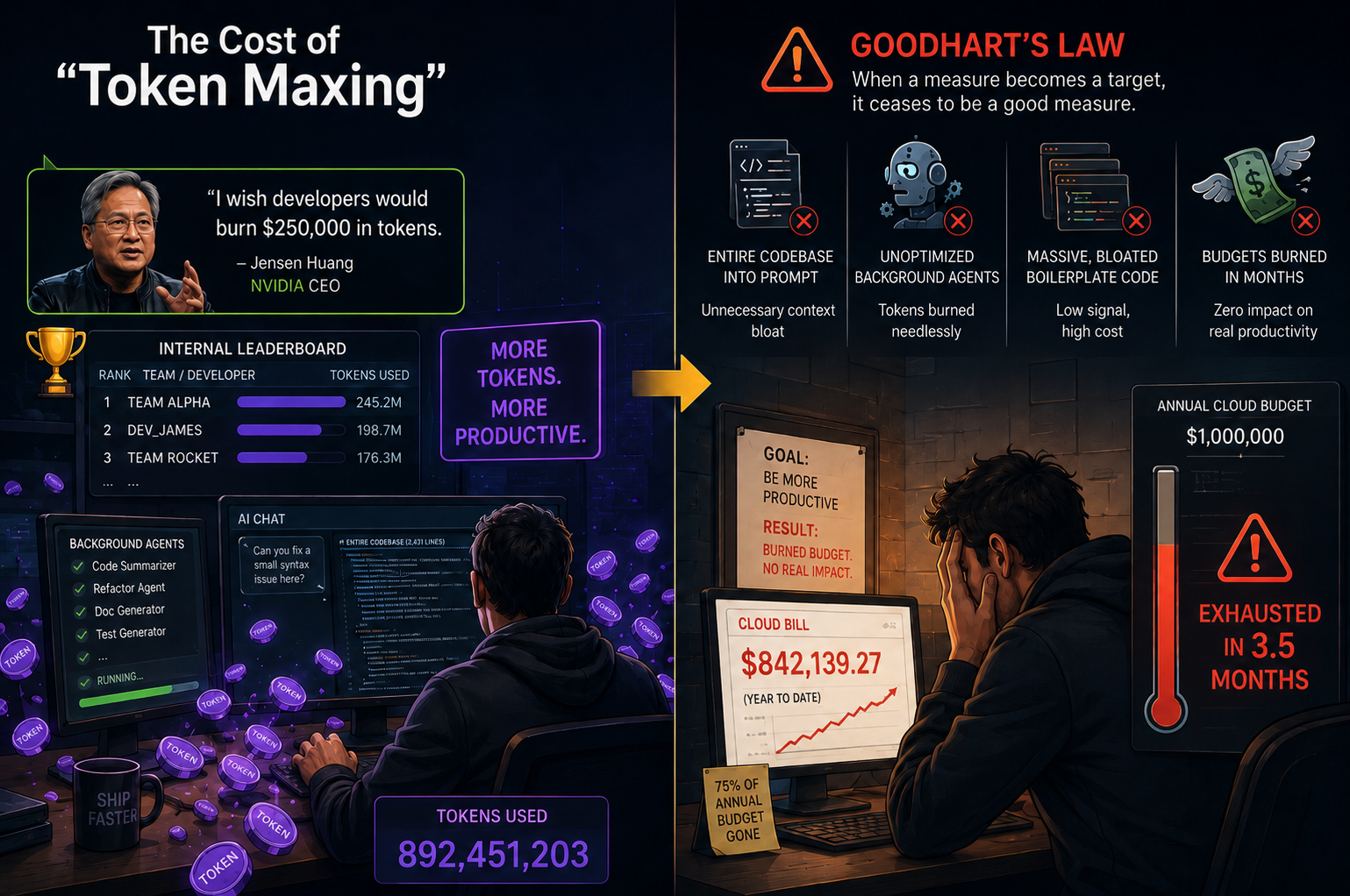
Then, Goodhart’s Law struck with a vengeance: When a measure becomes a target, it ceases to be a good measure.
The enterprise consequences of Token Maxing became painfully clear on June 3, 2026, when CNBC reported that Uber blew through its entire annual AI coding budget in just four months. Because developers were incentivized simply to run tokens, they flooded system context windows with unoptimized background agents and entire monolithic codebase copies just to answer simple syntax questions.
As a result, Uber was forced to implement strict internal monthly caps starting at $1,500 per tool per employee. Priceline.com quickly followed suit, capping developers at $2,000 a month, alongside similar adjustments from Walmart, Amazon, and Microsoft.
Worse yet, Uber’s leadership discovered that higher token consumption didn't automatically move more projects into production. It simply translated human time into metered, open-ended API bills. This completely rewrites the classic "In-House vs. Augmented Teams" debate and further supports the “No Silver Bullet” idea from the classic “Mythical Man Month”. If an unoptimized process costs you thousands of dollars a month in blind token waste, your tooling overhead is actively destroying your margins. AI might compress timelines, but compute is never a zero-cost replacement for true developer discipline.
The Solution: Token-Efficient Engineering
This economic shift is exactly why our original thesis still holds. AI makes humans faster, but the human is still best positioned to optimize context windows impacting token spend.
True operational agility now requires Token-Efficient Engineering: maximizing high-value architectural output per token spent. At Dev Teams On Demand (DTOD), we build with strict token discipline through a three-part framework:
- Tiered AI Tooling: Not every programming task requires a multi-billion-parameter frontier model. Asking an expensive, top-tier model to write unit tests is the economic equivalent of taking a rocket ship to the grocery store. Our teams route basic code autocompletion and repetitive boilerplate tasks to fast, lightweight local models, reserving expensive cloud token pools strictly for complex, high-leverage problems.
- Token-Aware Guardrails: Just as you wouldn't give a junior developer uncapped access to a production AWS environment, you cannot give developers uncapped AI credit lines. We budget a standardized, tightly managed compute overhead into our workflows, backed by strict organizational budget caps to ensure total cost predictability.
- Context Optimization: The ultimate bottleneck for token bleed is context curation. An untrained engineer copies and pastes a 2,000-line file into a prompt to fix a 5-line function. A token-efficient engineer isolates the specific block, strips out the noise, and feeds the model exactly what it needs to see.
Margin is the New Metric
The metrics of engineering success have changed. Speed still matters, but efficiency dictates survival. Now that the tech industry is hooked on AI, we have to be significantly smarter about the compute we consume.
As a flexible development partner, DTOD doesn’t just scale your team's headcount; we protect your bottom line. By ensuring our developers build with deep token discipline, we ensure that AI hyper-accelerates your product timeline without hijacking your cloud budget.
The era of cheap, flat-rate AI experimentation is officially over. Welcome to the era of token-efficient engineering.
Is your engineering team ready for usage-based AI? Let’s talk about building with token discipline.
