
Managing software engineering teams at scale is no easy feat, especially in 2026, where the pace of innovation demands both agility and precision. For CTOs, tracking the right metrics is critical to ensuring your team delivers optimized results while remaining focused and motivated. This guide explains the core metrics that signal true engineering productivity and offers actionable steps for improvement.
Lead Time: From Idea to Deployment
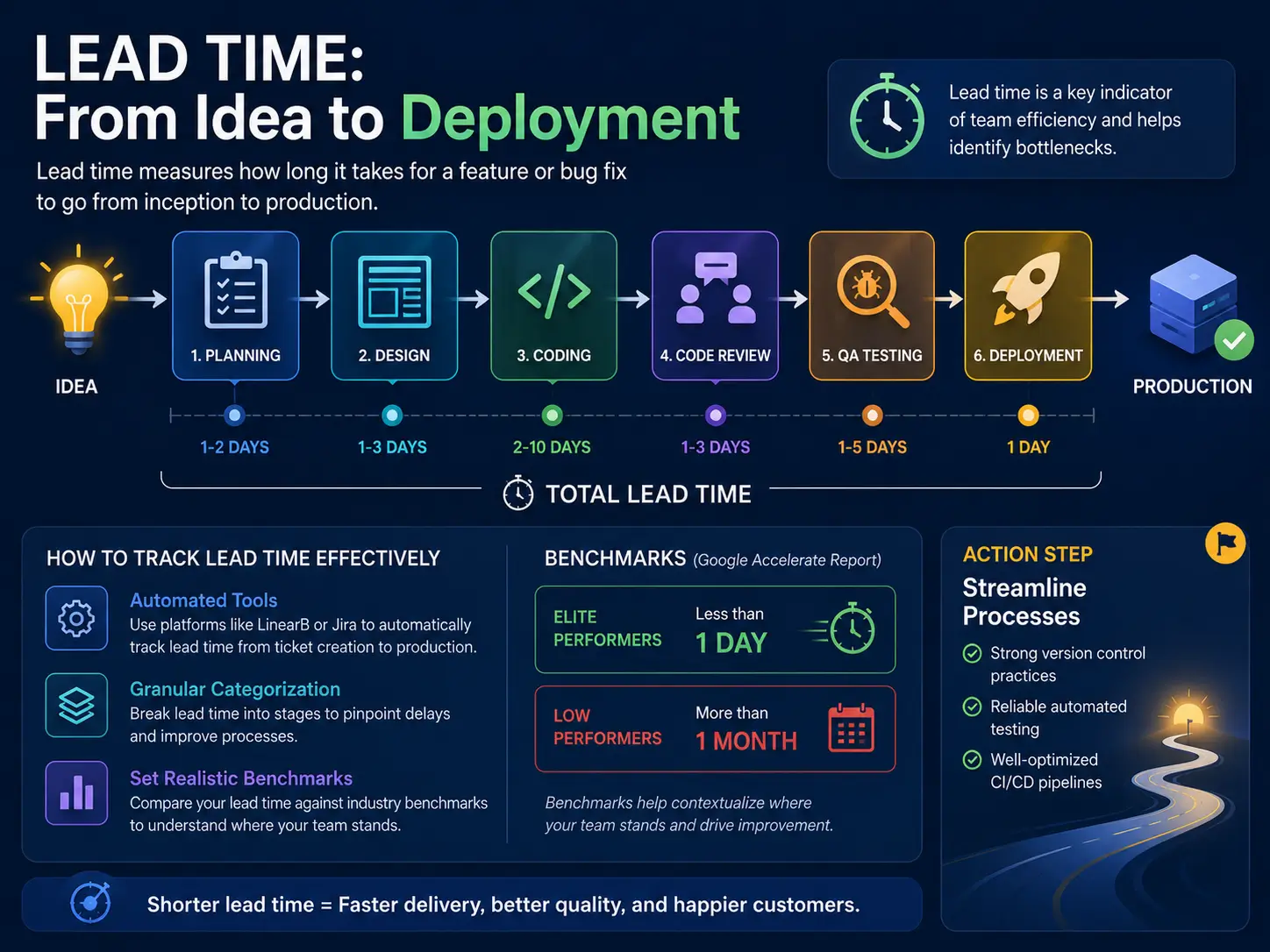
Lead time measures how long it takes for a feature or bug fix to go from inception to production. It’s one of the most important indicators of team efficiency because it encapsulates both technical execution and organizational processes. A long lead time often signals bottlenecks in development, code review, or deployment cycles.
How to Track Lead Time Effectively
- Automated Tools: Leverage platforms like LinearB or Jira to calculate lead times from ticket creation to production automatically. This eliminates manual guesswork and reflects accurate results.
- Granular Categorization: Break lead time into stages, such as planning, design, coding, code review, QA testing, and deployment. Understanding where delays occur is the first step to improvement.
- Set Realistic Benchmarks: According to data from Google’s Accelerate State of DevOps Report, elite performers achieve lead times of less than one day, while low performers may exceed a month. Benchmarks help contextualize where your team stands.
Action Step: Streamline Processes
Good lead time usually means good version control practices, reliable automated testing, and well-optimized CI/CD pipelines.
Deployment Frequency: Deliver Quality, Fast
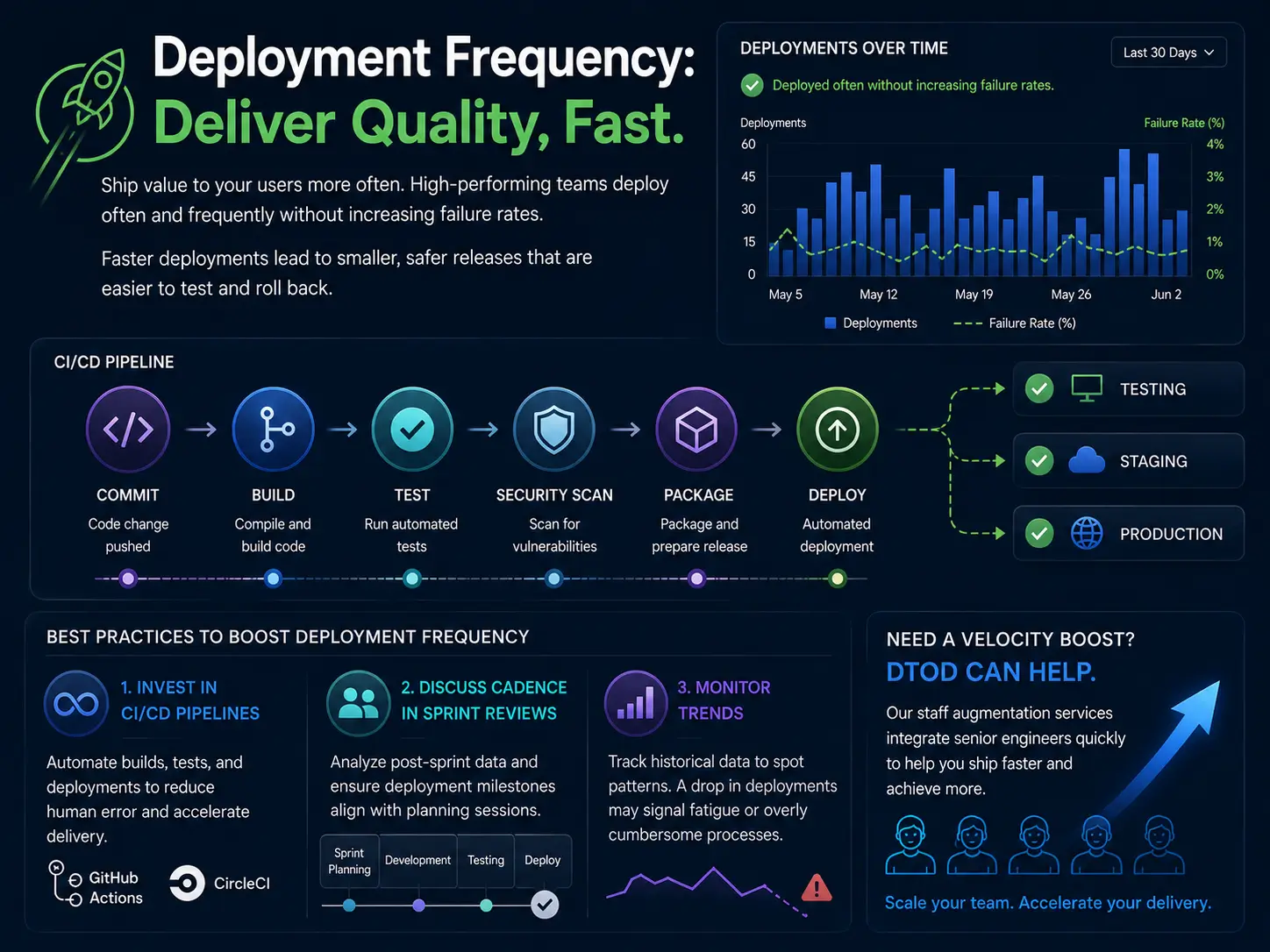
Deployment frequency quantifies how often your team ships code. Some high-performing teams deploy updates multiple times per day, and contrary to popular belief, doing so doesn’t inherently increase failure rates; faster deployments often foster smaller, less complex releases that are easier to test and roll back.
Best Practices to Boost Deployment Frequency
- Invest in CI/CD Pipelines: Automating deployments reduces human errors and speeds up the entire process. Platforms like GitHub Actions or CircleCI make setup straightforward.
- Discuss Deployment Cadence in Sprint Reviews: Analyze post-sprint data to identify if deployment milestones matched planning sessions.
- Monitor Trends: Use historical tracking data to observe frequency changes. If deployments are dropping, it may indicate developer fatigue or overly cumbersome processes.
For teams struggling with pace, DTOD's staff augmentation services can integrate senior engineers quickly to turbocharge your timelines.
Mean Time to Recovery (MTTR): Measuring Resilience
Errors and failures are inevitable, but how quickly your team resolves them can make or break customer trust. Mean time to recovery (MTTR) captures the average time it takes to restore service after an incident. While other metrics focus on development output, MTTR reflects how agile and well-prepared your team is under pressure.
Actions to Reduce MTTR
- Enable Alerts: Tools like PagerDuty ensure the right engineers are informed instantly when critical systems go down.
- Run Post-Mortems: Document lessons learned from downtime events and share best practices regularly to avoid repeated mistakes.
- Focus on Observability: Adopt tools such as Datadog or New Relic to provide real-time insights into application performance. Fast detection leads to faster fixes.
Elite performers typically resolve incidents in less than an hour. If your MTTR is high, it might be worth examining your incident management workflow for opportunities to implement automation or better logging practices.

CTO-Level Insight: Combining Metrics for Impact
Tracking metrics in isolation often leads to misinterpretation. The key is correlating insights across multiple data points. For example, pairing deployment frequency with MTTR can reveal whether pushing faster updates is indeed improving reliability,or adding risks. Similarly, tracking lead time alongside cycle-time trends can expose bottlenecks that impede your ability to scale engineering efforts sustainably.
For CTOs, the big takeaway is clear: Engineering velocity is not just about shipping faster; it's about shipping better. By aligning team strategy, technology investments, and engineering practices to minimize lead time, maximize deployment frequency, and reduce MTTR, you create a virtuous loop of development efficiency and resilience.
When you partner with Dev Teams On Demand, our experienced engineers can help you embed these metrics into your team’s operations. Combining technical expertise and structured processes, together we’ll ensure your engineering team is set up to stop searching and start building. Learn more at Dev Teams On Demand.
